A primer on the causal mask
The confusion about the causal mask already starts with its name. The original Transformer paper
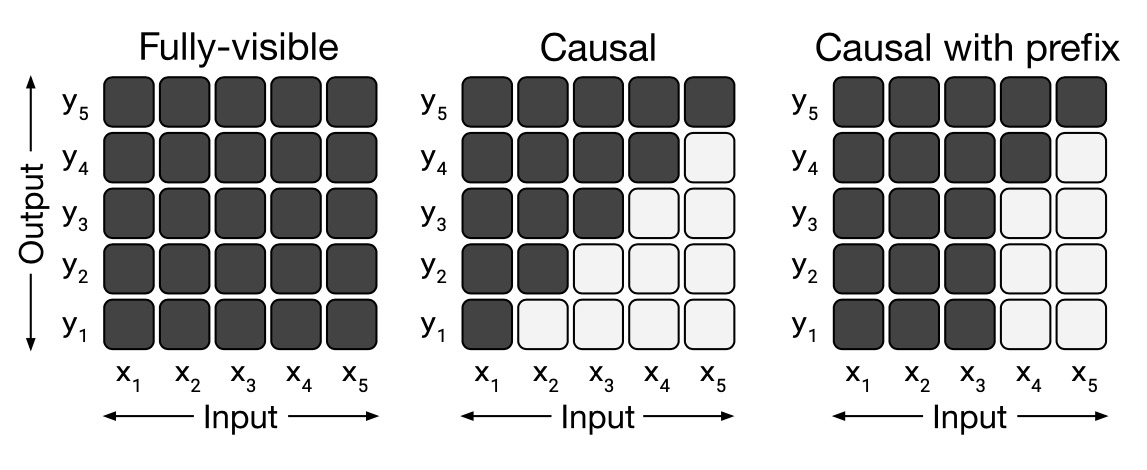
When solely looking at inference time, what we ideally want is full attention, i.e. every (generated) token can attend to every (generated) token (Figure 1, left). This is the no-mask regime, where the attention weights are not modified at all. Yet, all LLMs also use the causal mask at inference time since omitting the mask would lead to a distribution shift between training and inference, thus impairing performance. Since the causal mask is needed at inference time because it was used during training, a natural question to ask is: Why do we need the causal mask during training?
2On the necessity of the causal mask
For brevity's sake, we will focus on the GPT-style pre-training regime
To illustrate my point, suppose we have a sequence of tokens $$x_1, x_2, x_3, x_4$$ and we want the model to use tokens $$x_1, x_2, x_3$$ to predict token $$x_4$$. We need to prohibit tokens from attending to token $$x_4$$ when predicting token $$x_4$$, but we do not need to prohibit token $$x_1$$ from attending to tokens $$\{x_2, x_3\}$$, or token $$x_2$$ from attending to token $$x_3$$, which is exactly what the causal mask does. Instead of a triangular mask, using a block-sparse mask would suffice to prevent information leakage from future tokens, while allowing for all tokens in the context to attend to each other.
The illustration above only depicts the case of a single token prediction during training, raising the question of whether the point holds for parallel training as well. In fact, the causal mask is neither needed for parallel training, nor for teacher-forcing, and a block-sparse mask suffices for both.
3What about PrefixLMs?
We can motivate the use of block-sparse masks by looking at PrefixLMs
This masking procedure is specifically tailored towards the regime of sequence-to-sequence tasks under explicit supervision. However, the great abundance of textual data available on the Internet is unlabeled and largely unstructured, in which case PrefixLM training involves randomly splitting text into prefixes and targets. In this case, causal language modeling leads to much denser supervision than prefix language modeling, since the prefix does not provide a direct supervisory signal to the model.
This motivates a procedure that benefits from both dense supervision as well as full attention: Taking each token as the sole target and using all previous tokens as the prefix. This is exactly the block-sparse mask and nothing inherently prohibits parallelization in this regime. However, the block-sparse mask depends on the position of the token in the sequence, which means that a naïve implementation would require $$n$$ times as much memory and $$n$$ times as much computation, since everything after the first attention map computation is token-position dependent (where $$n$$ is the sequence length). Thus, the main challenge in moving beyond the causal mask is mitigating the memory and compute overhead that comes with that.