We now pay participants $300/month to use crowd-cast. Apply.
You really think we're going to scale data labelers to AGI?
While pretraining data acquisition has saturated and post-training overwhelmingly piggybacks on manual data labeling or handcrafted RL environments, the trillion-dollar question remains how we will get to the next set of model capabilities.
A billion people are predominantly working on computers, generating hundreds of billions of hours of behaviour-cloning data every week, yet that data remains uncaptured and ultimately lost.
Models can make sense of the predominantly garbage-filled internet, they can learn to produce long chains of thought from thousands of cold-start examples
1200h of AGI screencasts (and counting)
While crowd-code was our first attempt at capturing real-world long-horizon research engineering workflows by recording fine-grained IDE interactions, AGI-CAST went one step further by capturing raw screencasts of digital work.
Today, we publicly release AGI-CAST-0.6k on Hugging Face under the most permissive Creative Commons license, representing the largest public long-horizon dataset of human digital work consisting of over 600 hours of screencasts of researchers at p(doom).
More recently, we started capturing a paired dataset of screencasts, keylogs and mouse movement in order to train inverse dynamcis models to action-annotate unlabeled screencasts.
While great solutions exist for capturing such a paired dataset, no off-the-shelf solution sufficiently addressed our requirements of
being unobtrusive to the user when they go about their work, while transparently displaying recording status at a glance. We also needed a solution that supported privacy-preserving workflows
that, robust anonymization
...and millions more thanks to you?
We introduce crowd-cast, a native desktop application that allows anyone to participate in crowd-sourcing an action-annotated long-horizon behaviour-cloning dataset of computer work. Originally intended for internal rollout to construct a paired dataset of screencast observations and corresponding actions (key presses and mouse movement), we are now open-sourcing crowd-cast and allowing anyone to participate in crowd-sourcing.
On initial setup, the crowd-cast wizard asks you for a list of applications that should be recorded. An example list that we use internally includes a browser (Firefox), a text editor (Cursor) and a PDF viewer (Preview). We then use a separate browser (that is not part of the list of applications to be recorded, e.g. Chrome) for sensitive workflows such as E-Mails or messaging services. We found that this immensely helps adoption while still covering the majority of our working day. If you work on open-source projects, you will likely be surprised that you wouldn't be bothered by publicly streaming on YouTube with this setup (something we did for months).
We strive to make crowd-cast as unobtrusive as possible: by default, we capture five-minute segments, upload each segment to a private S3 bucket, and delete the local copy on segment boundaries. We will publish the cleaned dataset under the most permissive Creative Commons license (CC0). A live dashboard shows collection progress and summary statistics.
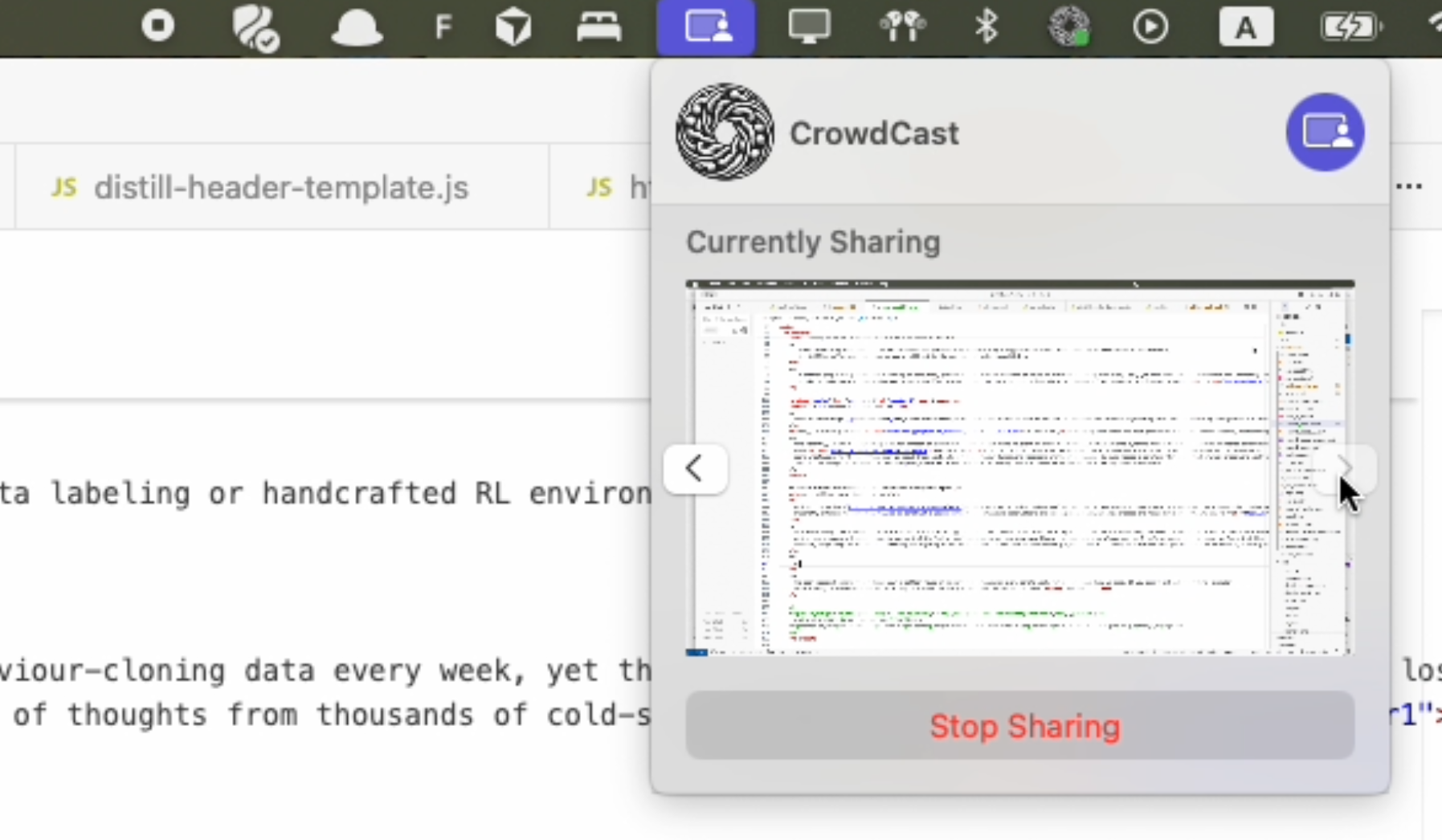
We synchronize actions per-frame and provide a script to render screencasts with action overlays. When the focused application switches to an application outside the predefined list, we capture a blackscreen and do not record actions (Figure 3). While the application tries to stay out of the user's way, recording status is always glanceable via the crowd-cast tray icon (Figure 2). The small circle indicates active recording (green), pausing due to the focused application being outside the predefined list (orange), and inactive recording (grey).
The open research community produces half a billion hours of uncaptured screencasts every single week, yet all of that data is lost. If you openly publish your work, consider applying to participate.